If you’re anything like me, you’ve spent the last 48 hours frantically refreshing the NYTimes, Politico, the Washington Post, Five Thirty Eight, & Memeorandum far more times than is healthy. This American election, more than any news event in my lifetime, has induced massive anxiety, fear, hope, and emotional turmoil (at least in those who understand how systems influence behavior and outcomes).
That said, the revelations that election polling had a sizeable, systemic miss this year (quite possibly worse than 2016) made me realize there’s an excellent opportunity to compare and contrast how election polls and SparkToro’s own data infrastructure operate.
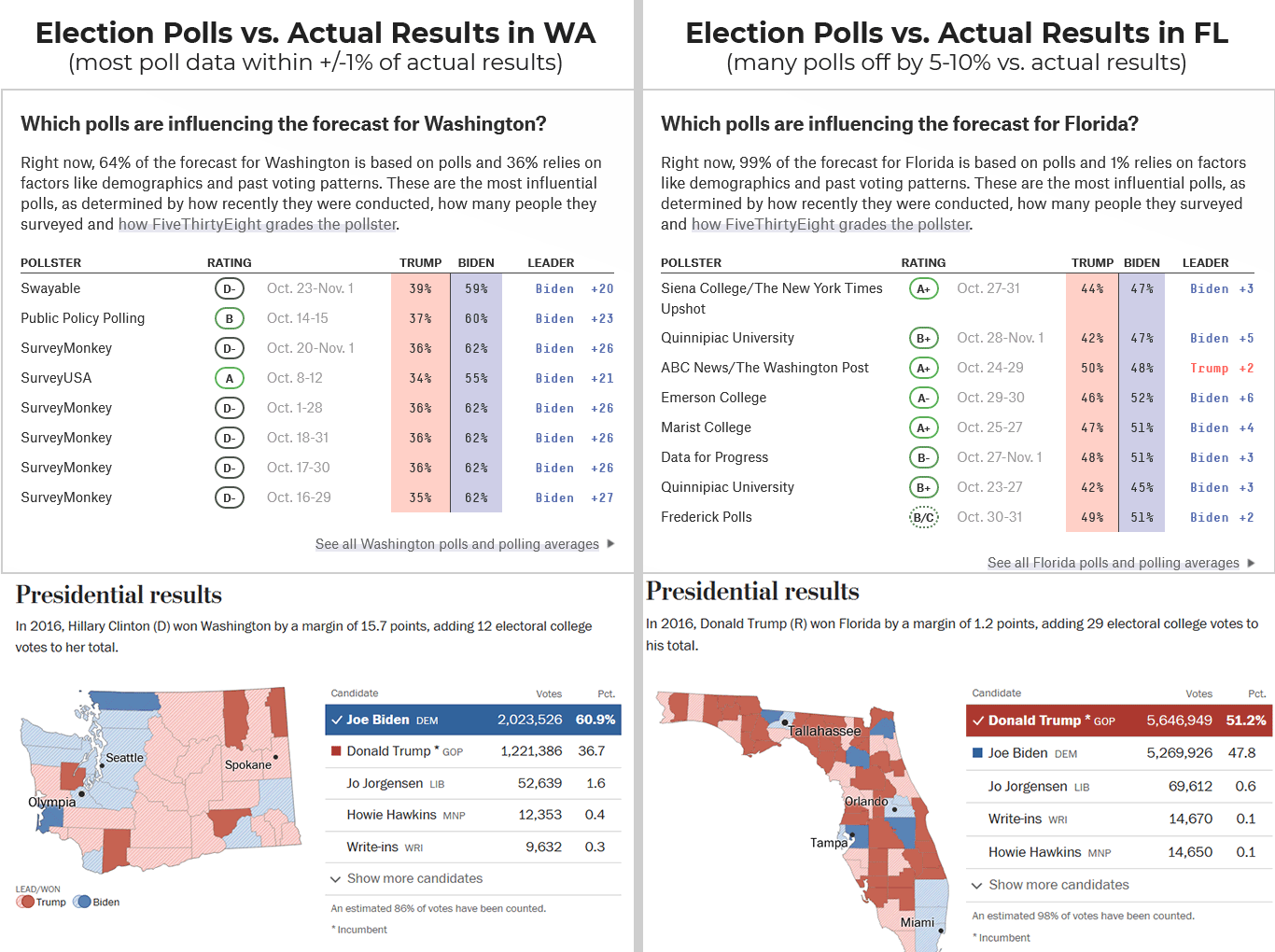
2020 polling “misses” in Florida were as large as 2X+ the reported margin of error, while polling in Washington was remarkably accurate
Election polling and market research both share a methodology: they conduct surveys with an attempt to include all the relevant audiences in proportion to the total population. Pollsters call, text, email, or collect data about a potential voter and their stated preferences. Any individual voter could, of course, misrepresent their views. But, in aggregate, collecting data about many thousands or tens of thousands of voters lowers the margin of error to generally small numbers. Even in the 2020 election, nearly every poll of every region and demographic will be within +/- 6-7% of actual behavior.
7% is frustratingly inaccurate for those who want answers to an election winner. But apply that same margin of error to the percent of people in a business’ target audience who listen to a particular podcast, follow a social account, or engage with a website, and you’ve got a very happy marketing team.
SparkToro’s data methodology is more like election results than election polls, because we’re capturing actual behavior: the accounts profiles follow, the content they share, the words and phrases in their profile/bio, etc. But, our coverage is more like election polling: we have a sample of any given audience that might vary from 2% to 20% of that audience’s true size.

When you click the Audience Insights tab in SparkToro, you’ll see rough buckets for size, behavior similarity, and confidence. Like an election pollster, our confidence is higher when the sample size is larger and the behavior similarity is more homogeneous. In the example above, SparkToro only has 308 people whose profiles include the word “finance,” and they have fairly diverse behaviors online, so we’re expressing relatively low confidence in the data.
Contrast that with the query below, where SparkToro has 2,303 profiles whose profiles include the word “software” in Seattle. This larger audience, combined with less diverse behavior, means we’ve got more confidence in the data.

When you want to understand the nuance of election polling or results, there’s often a breakdown of who was surveyed and how the weighting was achieved.
For example, here’s SurveyMonkey breaking down their sampling process for a 2019 poll:

SurveyMonkey shows distributions on things like party-leaning, age, race, gender, and registered-voter status. An observer might take issue with whether they’ve undercounted a demographic or political group, but the methodology is, at least, transparent.
SparkToro does something similar on the Audience Insights tab of any search you perform. We don’t collect or show race, age, ethnicity, or gender data (for a variety of ethical and legal reasons), but we do show data about profile content, words, phrases, hashtags, geography, and network coverage.

This data can be deeply insightful when attempting to understand a particular audience’s behaviors and SparkToro’s data about them. If you see that an audience (say, US software engineers) is engaging-with and following certain sources at relatively high rates, the data about who they are can be insightful, and key to making your marketing cases.

Above: Social accounts heavily followed by software engineer profiles in the US
For those 14,680 profiles that include the word “software engineer” and are located in the US, SparkToro has data about 25.4% of them on Github, 39% on Instagram, 29.9% on LinkedIn, 11.6% of those in San Francisco, 7.5% in Seattle, etc. All that information is in the Audience Insights tab, just like how you’d find election survey data in their methodology notes.
Brass Tacks: How Accurate is SparkToro’s Data?
The good news is that, like the reported election results, there’s almost no fraud or inaccuracies. We’ve got a robust system for excluding inactive, bot, propaganda, and spam profiles. Furthermore, all the data you see comes directly from the profiles we index. Unlike election polling, there’s no guessing or estimation. We don’t presume to know or present data about profiles that aren’t in our index, or people who match the search criteria but have no online presence.
Election results (like this one from Politico) show how people have voted, and the percentage who did so…

Similarly, SparkToro’s data shows how online profiles that match your search criteria behave, and the percent who’ve done so.

The big difference is in coverage. Election results will count every vote (ex-reality-TV star shenanigans aside). SparkToro cannot count every person who matches the search criteria, only those who have an online account with one of the 10 social networks we cover and are in our index (~75 million, mostly-English-language profiles today).
Hopefully, if you need to explain how SparkToro works to someone in your organization, a client, a colleague, or a skeptical friend, this piece will help. Our results are not nearly as important to the future of democracy and society as election results, but that’s no excuse for being any less clear about how they’re derived and how to interpret them.
If you’ve got questions, or just want to leave a comment to stave off pent-up election anxiety, I’d love to hear from you. And might I also suggest making some Spaghetti alle vongole? I’ve got a great recipe for you:

Nothing like carbs, clams, and vinho verde to brighten one’s spirits.